

ログインした後のページを何かしら取得したいと考えた時、まず考えるのはcurlの利用。でも、ログインしてcookieを取得して…という流れではなくて、crulを使わずログインしたページを取りたい!という時があって、それについて調べたので、今回も記録。
xpathの利用で使おうと思ってのことだけど、今回はそのログインしたページの取得だけ記載しておく。
cookieをまず取得する
取得したいページにまずはfirefoxでログインする。すると、ログインしたページが表示されているので、firefoxではcookieを取得している状態。
このブラウザから、cookieを取得するわけだけど、どこでわかるの?って話なんですけども、1.右上のメニューボタン→2.設定→3.プライバシー→Cookieを個別に削除する を押す
その後、ログインしたページのドメインを検索すると保有するcookieが見れる。
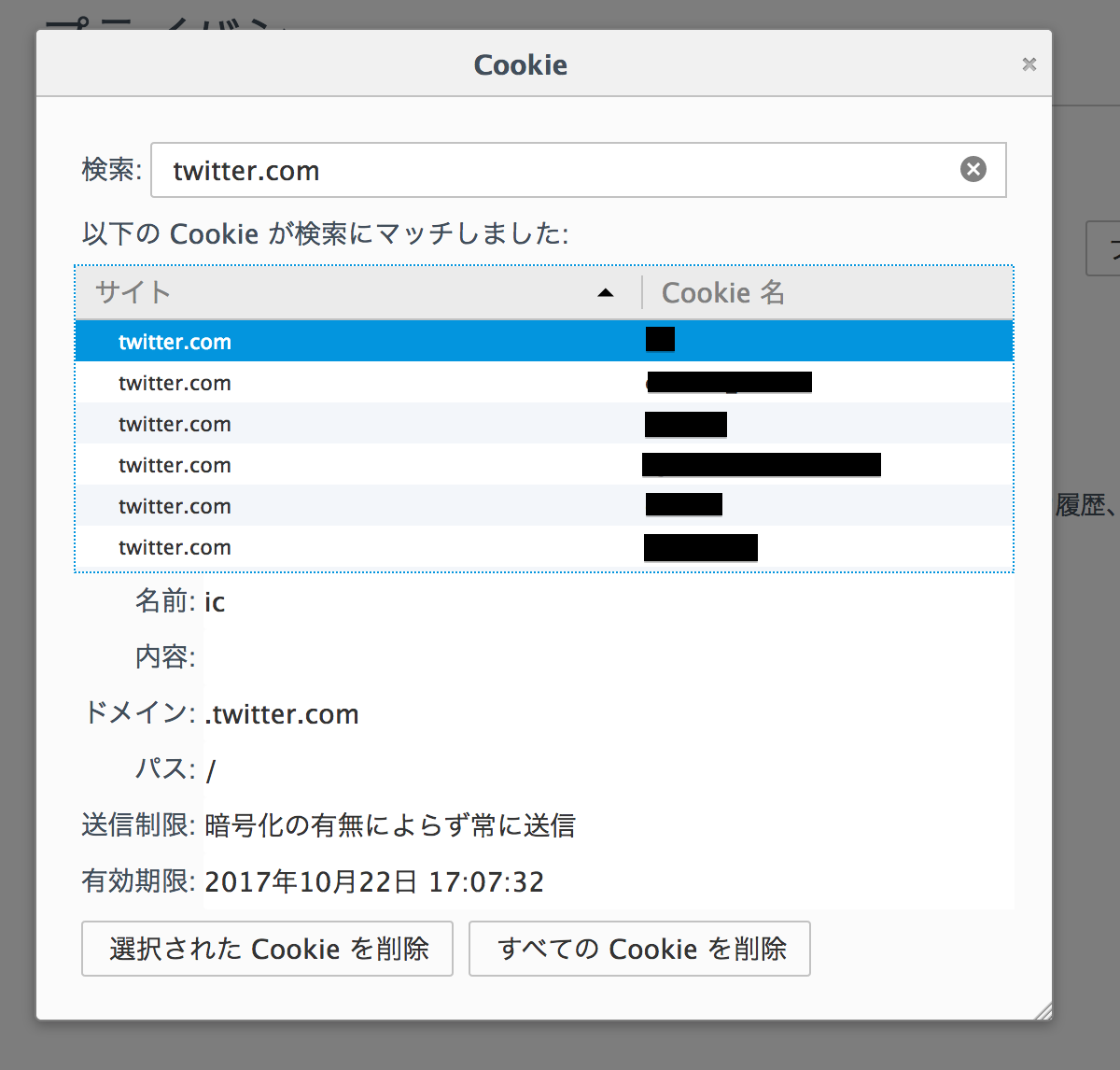
手当たり次第ぶちこんでアクセスすると、ログインページを取得できる
file_get_contentを実行する前にオプションを設定すると、cookieを埋め込んだ状態でアクセスできるので、ログインページを取得することができる。
以下、サンプルとする
$options = array(
'http'=>array(
'method' => 'GET',
'header' =>"Cookie: _gat=fdafdas;_ads=fdafsad;"
///cookieか各要素名に=で内容を入れ、; で区切る
)
);
$context = stream_context_create($options);
$url='https://hogehoge.com';
$source = file_get_contents($url, false, $context);
//$sourceをxpathで読み込んで、スクレイピングを実施するログイン状態は永遠ではないので注意
cookieは有効期限があるので、この状態でループ文での長い巡回は、いずれログアウト状態のソースを取得することになります。
一定期間をめどに使うのはよいですが、ずっとは状態が続かないので、そこに注意した上で、ソースの取得を行っていければと思う






