
これまではCSVを読み込んでグラフを作っていましたが、そもそもCSVなんて日常使っていないし、使うつもりもたぶんないし、エクセルも使わないし、mysqlしか使ってないじゃないかとふと気づきました。そっちが便利そうだし。なので、今回はmysqlでデータを取得して、pandasでpyplotできっとグラフができると思って頑張ります

データを例のごとく作成する
ひとまず、これまで使っていたあのcsv(https://webtopi.biz/archives/938 参照)のうち、number,pieces,us_priceを取り除いて、number,piecesに小数点が入ってるのがむかつくので除去して、データベース用のテーブルにぶち込んだところから始めます。
ただ、ちょっと操作メモだけ以下に記載
#該当3つだけをdata4とか、適当に名前つけた変数にいれる
data4=data[["number","pieces","us_price"]]
#整数に変えたいカラムを型変更、つまりキャストして、また別の変数にでもいれておいて
data5=data4.astype({'pieces': int,'number':int})
#csvに出力
data5.to_csv("./unko.csv")
#以下、中身
number,pieces,us_price
10251,2380,169.99
10252,1167,99.99
これを先方に(をつけて、最後に),をつける置換をして
(number,pieces,us_price),
(10251,2380,169.99),
(10252,1167,99.99),
で、ちょっといじって
(number,pieces,us_price)
values
(10251,2380,169.99),
(10252,1167,99.99)
とこんな感じからデータベースに入れるクエリを作成。numberは重複してそうなので、
primary key をnumber にしたあと、insert ignoreでぶちこんどけばおk。
どうせテストだしmysqlに接続してデータを取得する
普通に接続して普通に取得します
#db_data.pyに、あらかじめ接続用のデータを変数にいれてます
import db_data as local_db
import mysql.connector
import pandas as pd
try:
#古いバージョンのデータベースに接続する際は、shakehandがうまくいかないので、use_pure=Trueをつける
db = mysql.connector.connect(user=local_db.USER,password=local_db.PASSWORD,host=local_db.HOST,database=local_db.DATABASE,use_pure=True,port=local_db.PORT,charset="utf8")
sql='select * from python_test.sample_table order by pieces asc'
#pandas用に読み込み。sql文、dbの接続状態でいける
df_read = pd.read_sql(sql, db)
#ここからはいつもどおりの描画
df_read.plot.scatter(x="pieces",y="us_price",grid=True,color"c")
except mysql.connector.Error as e:
db.rollback()
finally:
db.close()以下実行結果
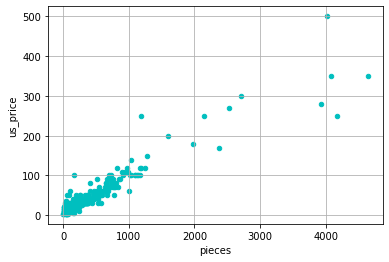
ちゃんとmysqlからデータを抜いたもので、グラフ描画ができました。
pandasでは、mysqlでデータを抜いて、fetchallした状態では読み込むことができないので、ちゃんとpandas用のmysqlの読み込みを使う必要があるようです。






